돌에 새겨진 지능
인류는 지금 미친 짓을 하고 있다. 도시만 한 데이터센터를 짓고, 옆에 발전소를 세우고, 위성 네트워크를 띄우고, 수백 킬로와트를 먹어치우는 슈퍼컴퓨터 방을 액체 냉각으로 식히고 있다. AI를 돌리기 위해서. 이게 미래라고 믿으면서.
하지만 역사는 다른 이야기를 한다. 기술 혁명은 언제나 괴물 같은 프로토타입으로 시작했고, 실용적인 돌파구가 나타나면 그 괴물들은 순식간에 사라졌다. ENIAC을 기억하는가? 방 하나를 가득 채운 진공관 괴물. 컴퓨팅의 마법을 보여줬지만, 느리고 비싸고 커질 수 없었다. 트랜지스터가 나오자 모든 게 바뀌었다. 워크스테이션, PC, 스마트폰으로 진화했다. 세상은 ENIAC을 더 많이 만드는 대신 넘어서는 쪽을 택했다. 지금 우리가 짓고 있는 GPU 데이터센터가 바로 AI의 ENIAC이다. 작동은 한다. 마법도 보여준다. 하지만 이게 끝은 아니다.
이 글을 계속 읽기 전에, 아래의 사이트에 가서 아무 질문이나 던져보길 권한다. 30초면 된다. 몸으로 느껴봐야 한다.
chatjimmy.ai
엔터를 누르는 순간 답이 와 있는 LLM이 등장했다. 그동안 우리는 AI에 랙이 있는 게 당연하다고 여기며 살아왔다. 그래서 이건 수치로 설명되지 않는 생소한 충격이다.
범용 컴퓨팅이 세상을 바꾼 건 빠르고, 싸고, 만들기 쉬워졌기 때문이다. AI도 똑같은 길을 갈 것이다. 문제는 지금의 AI가 그 길에서 한참 벗어나 있다는 거다. AI에게 질문을 던지면, AI는 턱을 괴고 한참을 생각한다. 코딩 어시스턴트는 몇 분간 멍하니 있다가 답을 내놓고, 몰입을 깬다. 찰나의 반응이 필요한 순간에도 느긋한 응답만 돌아온다. AI와 대화하는 건 아직 국제전화 같다. 말하고, 기다리고, 또 기다리고. 이 지연이 인간과 AI 사이의 벽이다.
비용 문제는 더 심각하다. 지금의 AI를 돌리려면 엄청난 장비와 돈이 필요하다. HBM 스택, 복잡한 입출력, 케이블, 액체 냉각, 첨단 패키징, 3D 적층. 왜 이 모든 게 필요한가? 기억하는 곳과 생각하는 곳이 따로 놀기 때문이다.
이렇게 비유해보자. 당신의 뇌는 서울에 있고, 기억은 전부 부산 창고에 있다. 뭔가를 떠올릴 때마다 KTX를 타고 부산까지 가서 꺼내와야 한다. 현대 AI 하드웨어가 정확히 이 구조다. 메모리(DRAM)는 용량이 크고 싸지만 칩 바깥에 있어서, 접근하는 데 칩 안쪽보다 수천 배 오래 걸린다. 그렇다고 연산 칩 안에 DRAM을 넣을 수도 없다. 공정이 다르니까. 이 모순이 AI 하드웨어의 모든 복잡함을 만든다. 서울-부산 왕복을 줄이려고 HBM이라는 고속철을 깔고, 3D 적층이라는 고층빌딩을 세우고, 액체 냉각이라는 에어컨을 돌린다. 당연히 전기를 많이 먹고, 비용은 천정부지로 올라간다.
Taalas는 이걸 근본부터 뒤집었다. 기억을 부산에서 꺼내오지 않고, 뇌 안에 모두 심었다. 메모리와 연산을 DRAM급 밀도로 하나의 칩에 합쳤다. 그리고 한 걸음 더 나아가 모델마다 전용 실리콘을 만든다. 기성복이 아니라 맞춤 양복. 컴퓨팅 역사를 보면, 깊은 특화는 언제나 극한의 효율로 가는 가장 확실한 길이었다. Taalas는 그 원칙을 끝까지 밀어붙였다.
어떻게 가능한가? AI가 학습한 지식, 즉 가중치를 실리콘의 금속층에 직접 새겨 넣는다. 문자 그대로 돌에 지능을 새기는 것이다. 하나의 트랜지스터가 가중치를 품으면서 동시에 곱셈까지 해낸다. 기억하는 동시에 생각한다. 창업자 Ljubisa Bajic의 표현을 빌리면, 이건 "핵물리학이 아니라, 아무도 이 길로 가지 않았기 때문에 아무도 보지 못한 영리한 트릭"이다. 칩의 뼈대는 그대로 두고 금속층 두 개만 바꿔서 특정 모델에 맞춘다. 같은 몸에 다른 문신을 새기는 것. TSMC 6나노 공정으로, 두 달이면 실제로 돌아가는 카드가 나온다.
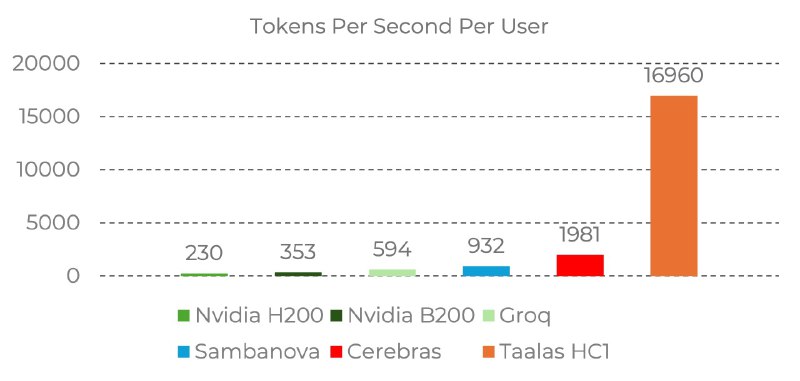
Llama 3.1 8B를 새긴 HC1 칩은 유저당 초당 약 17,000 토큰을 처리한다. Nvidia H200이 230, B200이 353, Groq 594, Sambanova 932, Cerebras 1,981. 다들 자전거를 타고 있는데 Taalas만 제트기를 탔다. 카드 한 장 200와트. 서버에 10장 꽂아도 2,500와트. 선풍기 수준이고, 30년 된 데이터센터에도 그대로 꽂힌다. 만드는 비용 20분의 1, 전기 10분의 1. HBM도, 첨단 패키징도, 3D 적층도, 액체 냉각도 필요 없다.
물론 공짜는 없다. 범용 GPU가 아무 노래나 틀 수 있는 스피커라면, Taalas 칩은 하나의 곡만 완벽하게 연주하는 오르골이다. 똑똑하지 않고, 모델이 바뀌면 새 칩을 찍어야 한다. 하지만 컨텍스트 크기 조절과 LoRA 파인튜닝은 가능하다.
그리고 결정적으로, 일상 업무에 충분한 모델의 임계점이 다가오고 있다. 프론티어 모델이 조금만 더 발전하면, 일상적인 반복 업무에는 꽤 오래 쓸 수 있는 시기가 온다. 그때 전용 오르골의 경제성은 성립한다.
Nvidia가 Groq을 200억 달러에 사들이고, SoftBank가 Graphcore를 삼키고, Intel이 SambaNova에 손을 뻗는 지금, 추론 전용 칩을 향한 큰 물결이 일고 있다. Taalas는 그 물결의 가장 급진적인 지점에 서 있다. 첫 제품은 실리콘에 새긴 Llama로 시작하지만, 봄에는 중형 추론 모델이, 겨울에는 프론티어 모델이 뒤따른다.
매우 빠른 AI는 전혀 다른 AI다. 천 분의 일 초 이하 지연이 가능해지면, 상상만 하던 시나리오들이 현실이 된다. 국제전화가 아니라 옆 사람과 뛰어가며 대화하는 체감. Taalas가 첫 모델이 프론티어가 아님에도 chatjimmy.ai를 베타로 연 건, 이 속도에서 뭐가 가능한지 직접 느껴보라는 자신감이다.
자율주행차는 0.01초 안에 판단을 끝내야 한다. 시속 100km로 달리는 차가 0.01초에 움직이는 거리는 28cm. 자 한 뼘. 그 안에 보행자를 인식하고, 판단하고, 핸들을 꺾어야 한다. 드론은 더 가혹하다. 초속 수십 미터로 날면서 장애물을 피해야 한다. 전투기의 fly-by-wire, 수술 로봇, 공장 로봇. 이런 환경에서 클라우드에 질문을 보내고 응답을 기다리는 건, 전장에서 본부에 편지를 부치고 답장을 기다리는 것이다. 네트워크 왕복 시간만으로 사람이 죽는다.
지금의 GPU 추론은 이걸 풀 수 없다. 수백 와트를 먹고 액체로 식혀야 하는 하드웨어를 드론에 넣는 건 냉장고를 자전거에 얹는 것이다. 로봇 안에, 자동차 안에, 드론 안에. 클라우드 없이. 지연 없이. 오르골이 진짜 빛나는 순간은 그 곡이 생사를 가를 때다.
우리는 아직 AI의 ENIAC 시대에 살고 있다. 거대하고 비효율적인 괴물들이 데이터센터를 가득 채우고 있다. 하지만 역사는 반복된다. 트랜지스터의 순간은 온다. 우리 손안에, 우리 주머니에, 우리가 타는 모든 기계 안에 들어가려면, AI는 빠르고 싸고 만들기 쉬워져야 한다. ENIAC의 확산은 일어나지 않았다. AI의 ENIAC적인 확산도 일어나지 않을 것이다.
AI 생태계는 새로운 접근을 필요로 한다. 그리고 이런 방향의 도전이 절실히 필요하다.
❤39👍6😱6